
AI progress trajectories
How fast will AI improve?
This is one of the key questions of our time, but few companies (outside of tech) and policy makers take this question seriously. We might see AI improve dramatically in a few years. We should take that scenario seriously.
Reasoning will improve: the scaling hypothesis
The big bet the AI industry is playing out right now is the scaling hypothesis. Turns out that if you make your AI model bigger, and throw more data at it, it gets better.
In fact, it gets better at a surprisingly predictable rate.
There is a that tells you what the test loss will be, given how much data, model size, and compute budget you have. Test loss is a measure of how good the AI is at predicting the next token. This simple model also tells you what is the best combination of data, compute and model size. So far this simple model has been predictive of AI’s performance across many orders of magnitude.
Now test loss isn’t everything. We cannot directly connect the test loss with specific capabilities or performance on reasoning tasks. But they are correlated.
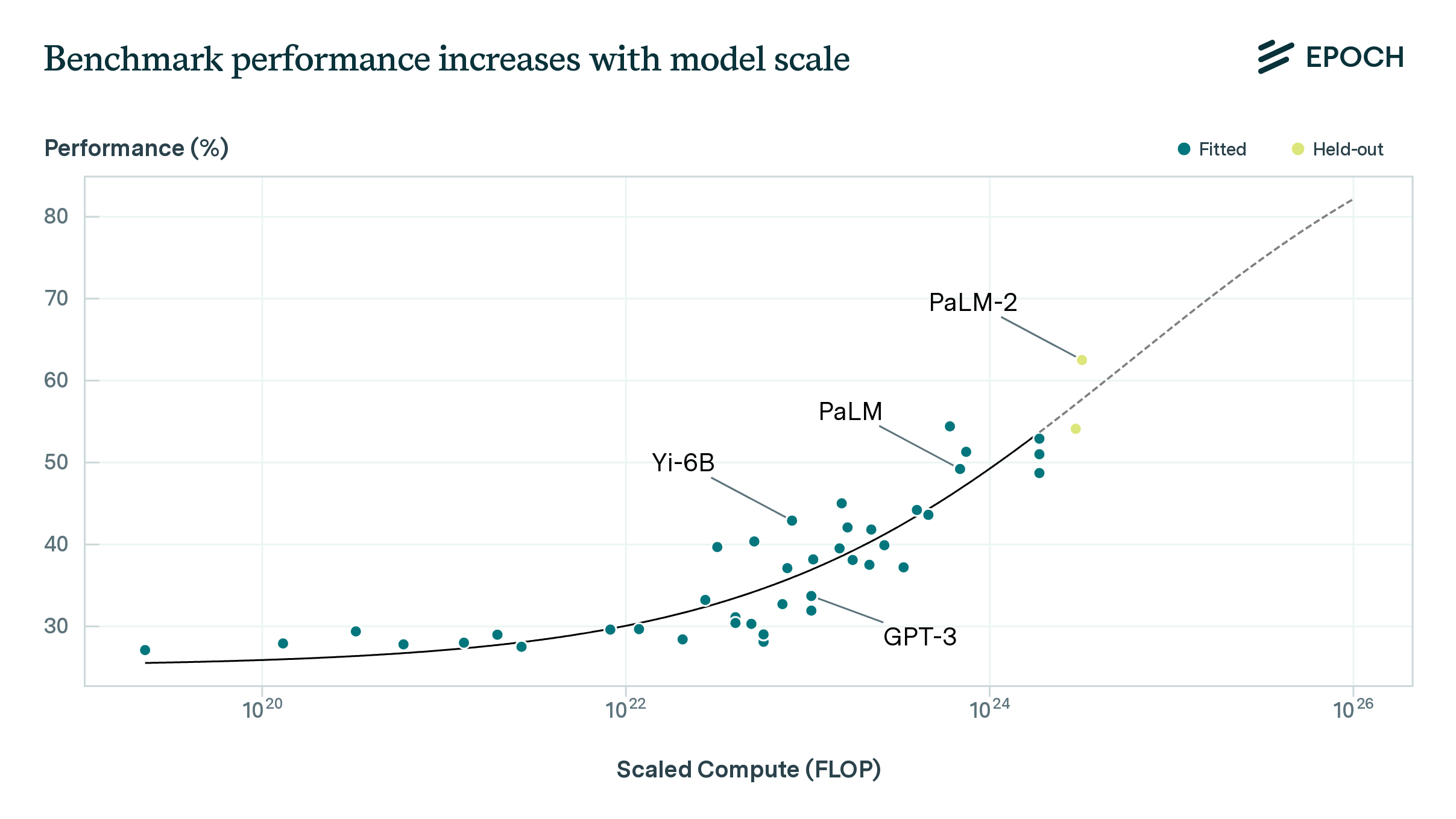
And our ability to predict the test loss, and the correlation between test loss and performance has been good enough to de-risk investments in bigger models. You can now go to your finance team, and tell them “I need $X amount to train an AI, which will be ~Y better than what we have now”. This has led to the big players in AI to make increasingly more aggressive investments.
For instance, Anthropic’s CEO expects that by the end of 2024 we’ll see $1B+ models , and in 2025 we might see $10B+ models.
 .
.
The scaling hypothesis is a Big Deal. What the scaling hypothesis really says is that we do not need scientific breakthroughs to make better AI; we just need more engineering. And many problems in engineering can be solved by throwing more money (like for GPUs and electricity) at the problem.
There are some reasons to suspect that the scaling law won’t hold. Dwarkesh Patal has where he takes on both sides of the scaling debate, and plays out a conversation. It seems like there are some reasons to be skeptical, but there is no concrete evidence demonstrating that the trends will not hold for a while longer.
Bottom line It seems to me that the scaling hypothesis is reasonable. The implications of this is that you should expect to see steady progress in the reasoning capabilities of AI until we get evidence to the contrary. Every ~2 years we should expect to see a jump in capabilities.
If the difference between GPT3 to GPT4 is similar to from GPT4 to GPT5, then we might get to commercially relevant reasoning agents with the next release or two. GPT4 is not quite able to make effective long term plans, and is therefore not yet able to automate work. However, its substantially better than GPT3.5. The scaling law tells us that GPT5 will be better again, and GPT6 will be better still.
The implication of this is that we might see substantial improvements in the progress of AI in a very short amount of time. I.e. by the end of the decade! We should build products and policies with this expectation in mind.