What I do: Copilots on a data platform
![]()
At Microsoft Fabric I am on the founding team of the copilots initative. Here we try to imbue the new flagship data platform (made public in Spring 2023) with AI capabilities. Imagine writing things like “please analyze this dataset for anomalies”, or “create a dashboard of this dataset showing sales projections” and actually getting timesaving and trustworthy results.
This has been a great opportunity to learn on how to build with the new LLM. Everyone is learning in parallel with the new wave of AI tech (LLMs), but I am working with many incredible colleagues who help me make sense of things.
You can see some of the initial features we will ship here.
What I did
Reinforcement Learning for Industry
2021-2023
Tags: Reinforcement Learning, Simulations
At Microsoft Bonsai I helped companies implement Reinforcement Learning (RL) solutions to solve their largest control problems.
The basic approach is pretty simple. Step 1: build a simulation. Step 2: train an algorithm to control that simulation. Step 3: deploy the trained algorithm on real hardware. Turns out that every one of those 3 steps is pretty hard
I first did this work as a client-facing AI Engineer, and later I switched over to Product Management, where I in charge of the core AI algorithms and capabilities. We tried tackling the sim2real gap, and made some progress. We focused on learning directly from data (“Offline Reinforcement Learning”), increasing robustness in the face of imperfect simulations, and accelerating training speeds.
Microsoft decided to discontinue this product, but I still believe in the approach. Having AI agents, pre-trained on simulations, control complex and high-dimensional processes is a better solution than relying on humans, who simply cannot make good decisions at this complexity.
Active Learning and Materials Informatics
2019-2021
Tags: Materials Informatics, Active Learning, Uncertainty Quantification
At Citrine Informatics I worked with some of the top materials companies in the world do better analytics on their materials data. I started as a data scientist and eventually become a tech lead, where I got to teams of data scientists and engineers.
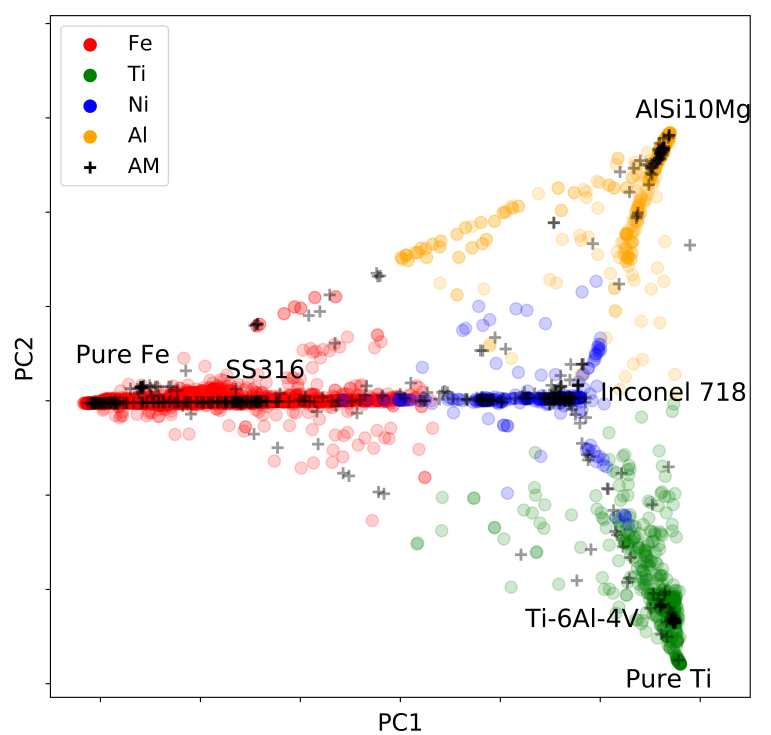
The core approach was to use bayesian optimization; if you can quantify how sure you are that X will happen for some specific process (e.g. If I heat this material at 600°C I know the tensile strength will be 400 MPa because we tried this many times, vs. I have no idea what happens if I anneal at 750°C), then you can focus your search on the areas where you aren’t sure what will happen, but there is high upside potential. The trick is therefore to build predictive models that have well calibrated uncertainty estimates.
Using this technique I (along with some fantastic and talented colleagues) helped various companies achieve breakthrough insights in different systems, ranging from glass, to metals, to polymers. Beyond the technical execution of specific projects I helped companies develop their AI strategies; working with executives to create a vision, setting up data collection practises, and training their researchers in data-driven exploration.
I can’t talk much about specific work I did, because most of it was highly secretive (I know.. very mysterious!), but I worked on these two project:
- Case study: Rapid Polymer Screening using AI
- Case study: Glass Development - Machine Learning Accelerates Research
And I was a co-inventor on a patent: Product design and materials development integration using a machine learning generated capability map
Automatic Text Extraction from Materials and Manufacturing Journal Articles
2016-2019
Tags: NLP, Information Extraction, Data Engineering Pipelines, Materials Informatics
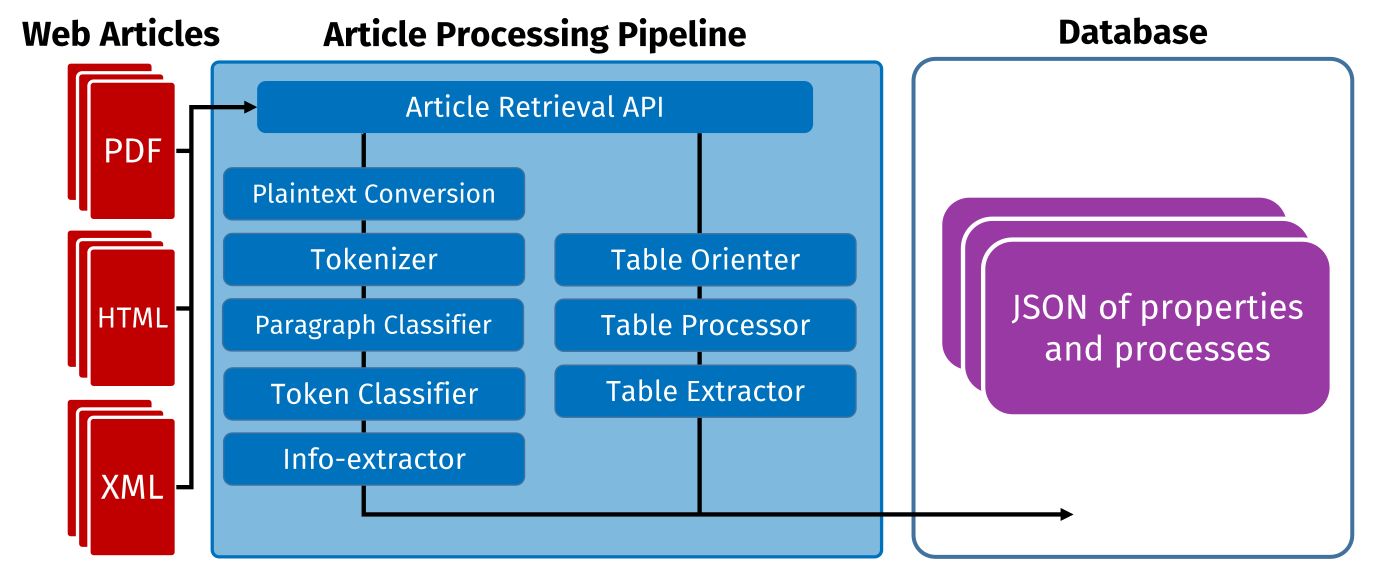
In the Olivetti Group at MIT we built systems to automatically extract information contained in materials science papers (the input ingredients, the process, the resulting properties). Once you have that dataset, there is a lot you can do like creating comprehensive maps of what has/hasn’t been tried to give other researchers new ideas, or automatically generate new synthetsis paths for materials.
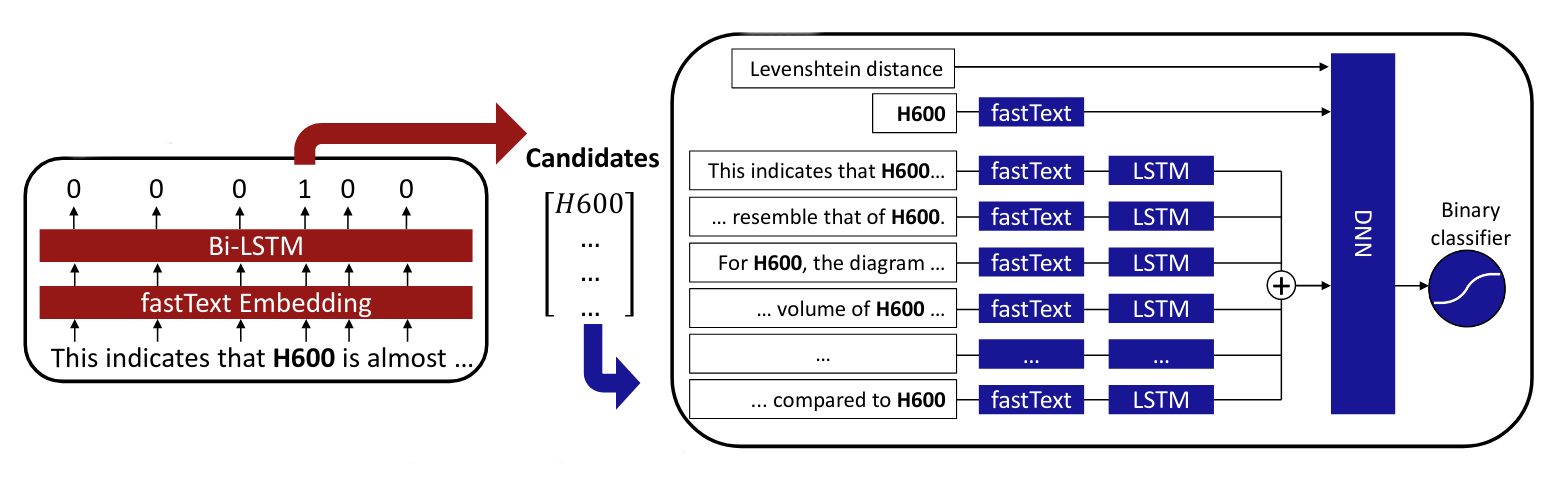
The technology has come a long way since then. We were using Word2Vec (in later pipelines; BERT), created our own LSTM-based Named Entity Recognition systems trained on painstakenly labeled data, built table parsers, and more.
You can read about this here:
- Inorganic Materials Synthesis Planning with Literature-Trained Neural Networks
- Manufacturing variability; effects and characterization through text-mining.